
Oct 20, 2022
Machine Learning as a Service, Part 1: The First Phase in Scaling for Hyper Growth

Director of Engineering, SupportLogic
Support Experiencemachine learningnext gen supportartificial intelligence
Read More

Siddharth Srivastava
Senior Software Engineer, SupportLogicIn previous installments of this MLaaS series, we’ve explored design considerations, endpoint management, data integration, and the deployment of API endpoints.
MLaaS has dramatically increased the speed at which we can launch new products. We can now deploy new ML models in 5 minutes, and run sentiment detection on any custom CRM field.
In part 3 of this series we’ll explore model monitoring, which includes alert, drift, and feature attribution detection. We’ll also dissect the platform used to streamline MLaaS.
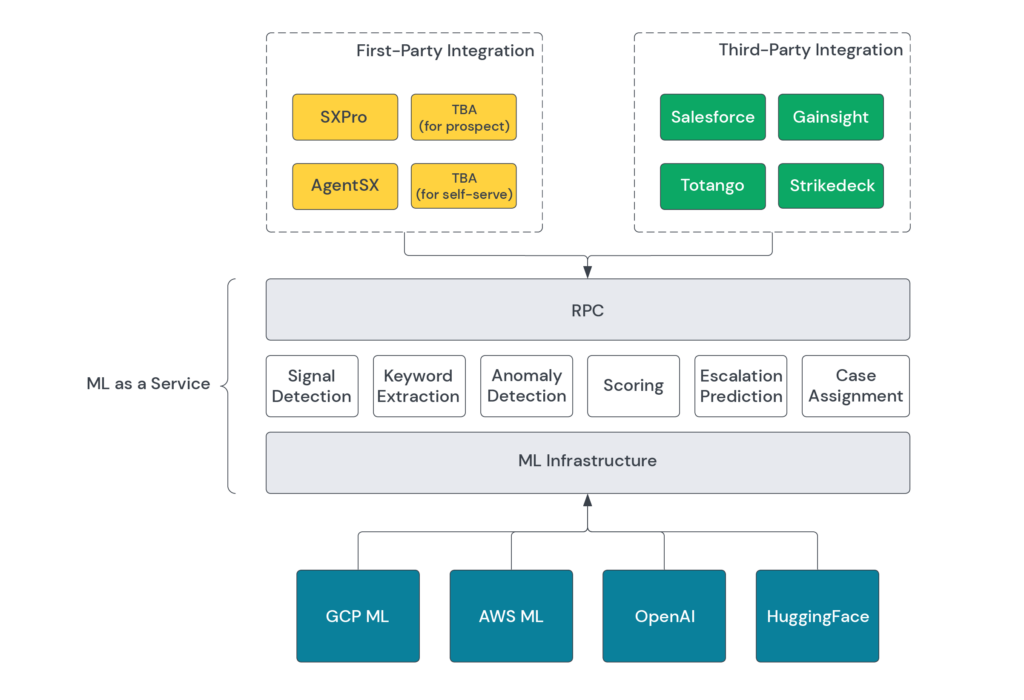
To understand the design choices, let’s start with the ML model and the data we use to train the model. We’ll then address the ML infrastructure needed for our modeling, move to MLaaS, and then to deployment.
ML infrastructure is important since many models are trained to specific customers and have unique experimentation requirements.
The Likely to Escalate (LTE) model is a gradient-boosted tree trained on the temporal data of customer case activity (and more).
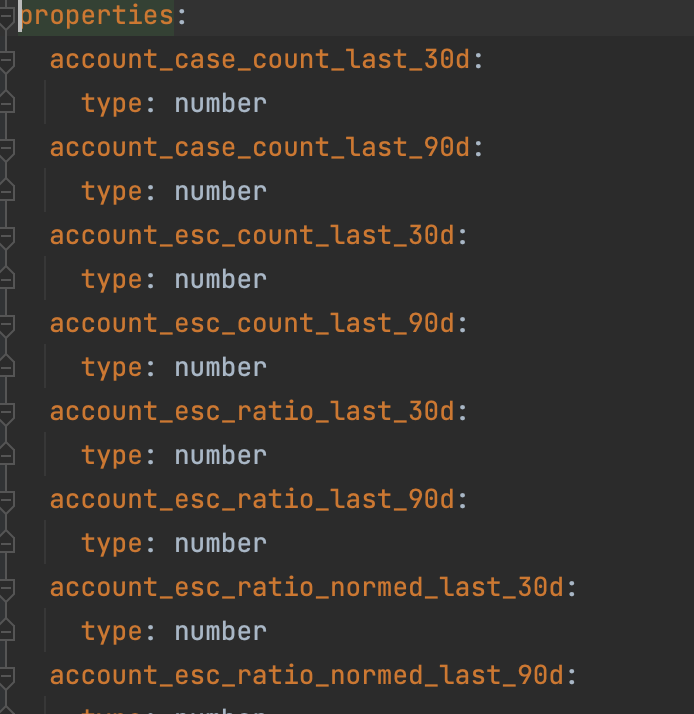
The data is mostly a timestamped dataset of customer case activity. We examine various case activities, sentiments, and attention scores at various timestamps of case history to create a snapshot of cases and use it for training. We also actively tinker with the present feature set and add more features every cycle to increase our overall metrics.
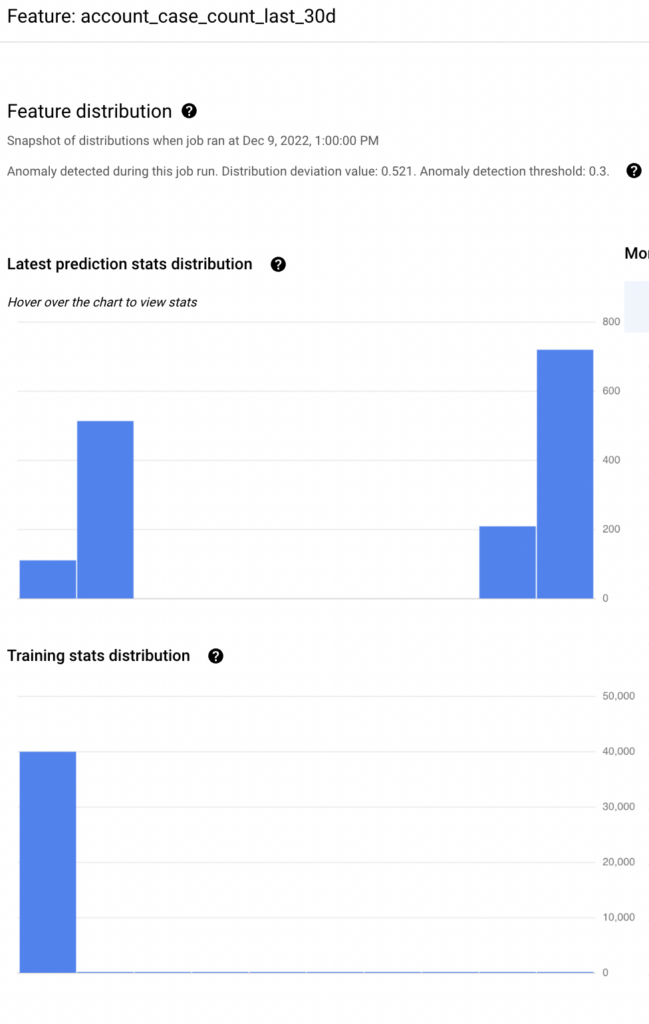
Because of the nature of both the data and model, our model and features can decay with time. Thus, features must be monitored and compared with training data to understand skew and drift. As production data distribution starts differing from what the model was trained on, our predictions will also get worse.
This system was designed to align not just with consumer applications but also with developers and data scientists. In other words, we wanted it to be easy to use by consumers as well as for training and productizing the model.
Data scientists need an array of tools for iterative experimentation and must be able to run big data workloads to load data and train the model. For this reason, we scaled model training for experimentation with different configurations, compared them, and built robust data pipelines that can be configured and reused.
We designed the microservice and deployment to be as lightweight as possible, but also followed all concepts of repeatability, rollback, and proper audit trail. The primary design consideration was a requirement to be able to rapidly deploy models by a data scientist without ops assistance.
Once a model is deployed, we want to make sure the model is performing at the same standard as in the training and evaluation setting. The following deviations are monitored in the feature set:
For all these considerations, we use Vertex AI as the platform for implementing the escalation model API and overall ML infrastructure.
Vertex has been touted by Google Cloud Platform (GCP) as an integrated platform for experimentation, model training, deployment, and monitoring. It includes suites of features beneficial to both data scientists and MLOps:
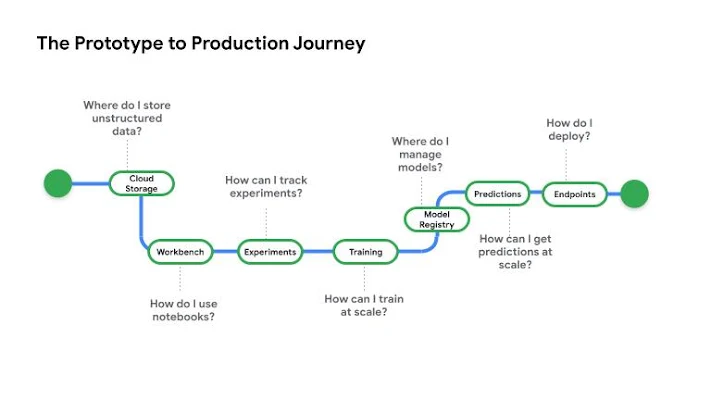
Vertex AI aims to solve challenges regarding many stages of a model’s development lifecycle. Streamlining all ops workflow allows us to focus on experimentation.
The following are various components that help ease the path from experimentation to production.
Let’s explore some shortcomings and comparisons to other infrastructure and discuss why we are using Vertex:
Vertex Endpoints can’t be scaled down to zero instances. Unlike CloudRun, Vertex endpoints cant be scaled to zero instances. Hence, they always incur some cost for running them AND we used vertex regardless of that because LTE models prediction works similarly to monitoring service. We periodically run this model for every open case which means we have deterministic usage of the API at a particular cadence all the time.
The escalation prediction model API uses a custom model built on our own docker container. We use a custom docker image as mentioned above, requirements for building a custom docker image for the vertex are the following:
We wanted to design deployment as lightweight while maintaining Ops principles of repeatability, rollbacks, and proper audit.
For deployment, we are using Terraform for those principles outlined above, along with the benefits of modularity and reusability. Once a terraform module is created, it can be used for different projects.
Terraform doesn’t have great support for Vertex, so a few modules are missing in the terraform registry. We compensated those by using terraform provisioners that wrap GCP AI python SDK around terraform apply and destroy.
Provisioners are ways to call user scripts during terraform apply and destroy.
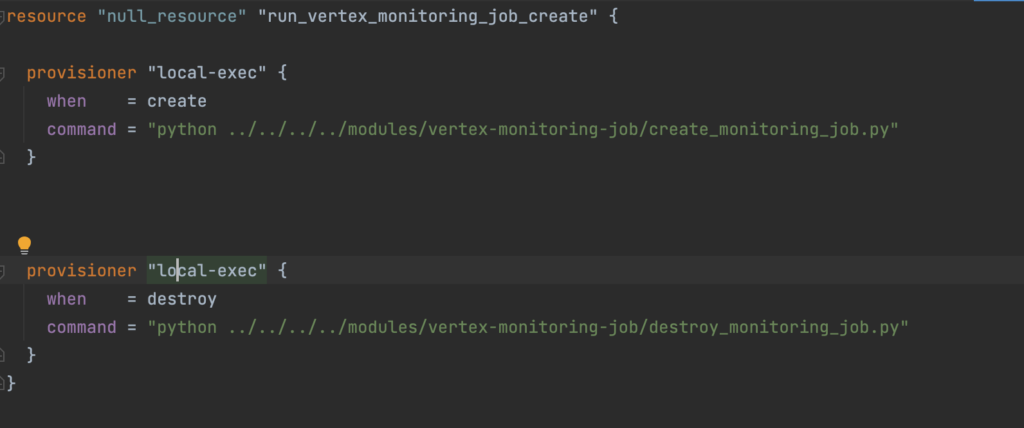
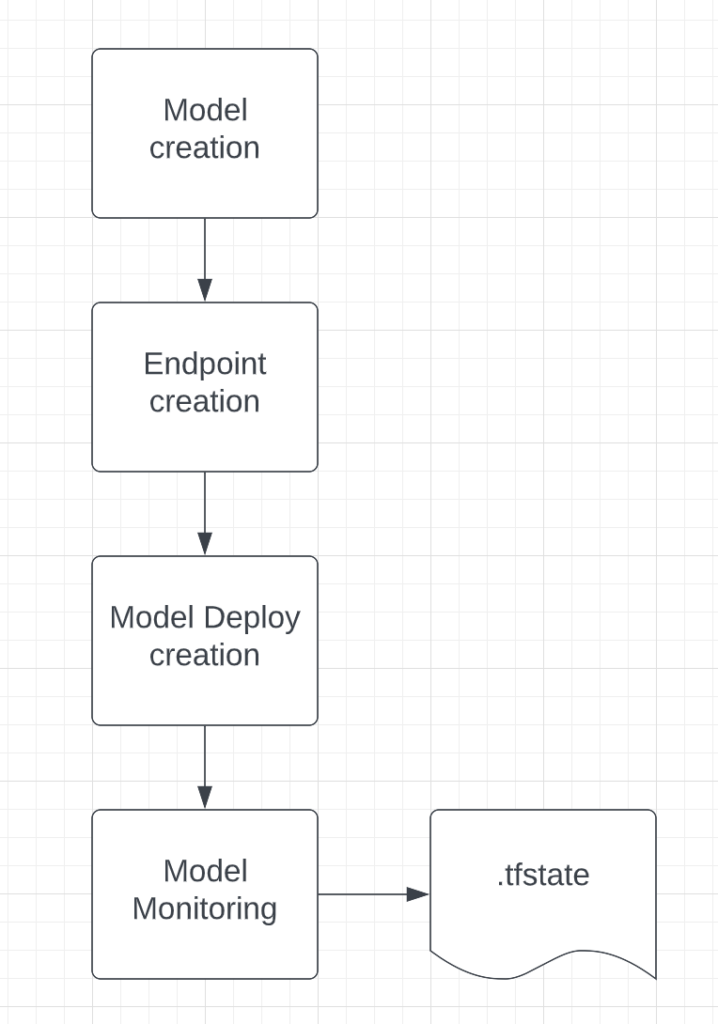
Terraform apply works in stages, first creating the Model and Endpoint then deploying the model to the endpoint, and then enabling the monitoring job on the endpoint.
Terraform destroy works completely opposite, first deleting the monitoring job then un-deploying the model from the endpoint, and then deleting both the model and endpoint.
MLaaS infrastructure not only helps us scale up and cross-pollinate different products (through MLaaS) but also makes experimentation easy, thus increasing the output of innovation and research.
Modern ML platforms are getting more streamlined, but not without constraints. Here is a summary of some of the lessons we’ve learned:
We are planning a suite of ML features intended to shorten the time from experimentation to production, including offloading training to a distributed training pipeline for the following use-cases:
This concludes part 3 of our MLaaS series – stay tuned for part 4 and be sure to revisit the previous installments.
Want the latest B2B Support, AI and ML blogs delivered straight to your inbox?


