
Oct 20, 2022
Machine Learning as a Service, Part 1: The First Phase in Scaling for Hyper Growth

Director of Engineering, SupportLogic
Support Experiencemachine learningnext gen supportartificial intelligence
Read More

Michael Larionov
Staff Data Scientist, SupportLogicAt SupportLogic, we’re building a machine learning suite to serve as a platform for empowering several ML products. In part 1, we laid out the motivation for building ML as a Service (MLaaS) as an efficient way to deliver AI for customer support.
In this article, we’ll take a deeper dive into how we built the services part of MLaaS. All of these ML products are running as microservices. Microservices are stateless and independent of the customer database, making them multi-tenant. However, with growing customer demand, these services must be scaled and managed efficiently without compromising lean practices. Read to see how the Cloud Run service by Google Cloud Platform (GCP), also our cloud provider, aligned with these requirements exactly.
One of the most important design considerations for ML services is that it is stateless and stays disconnected from our customer databases. All data must come from the request object. Every cloud provider, including GCP, has serverless offerings that are suitable for building ML Services. Since GCP is already in use, the natural choice was either Google Cloud Functions or Cloud Run. Cloud Run allowed us more customization to the container running the service. As a bonus, it was much easier to test locally than Cloud Functions.

Cloud Run is a fully managed, serverless platform for running code as a service. It builds containers from images picked up from the Container Registry and the containerized solution makes it possible to deploy any application. Cloud Run also uses Knative in the back end to auto-scale the container, which takes away the effort of orchestrating scaling via Kubernetes. It also comes with extensions on popular code editors like VS Code and PyCharm, which helps developers test their solutions locally before pushing to the cloud. The pricing model is also very attractive, since Google does not charge for the time service is not used.
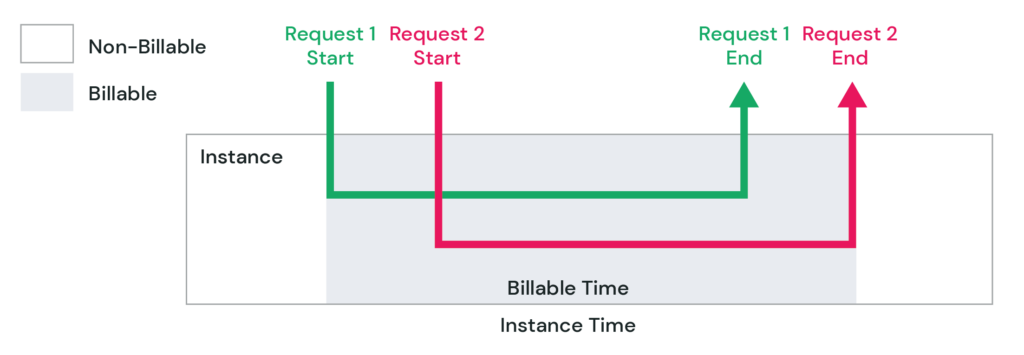
One of the core features of ML Services is multitenancy. Since the services do not access customer databases, the services also lack access to customer-specific configurations. So how do the ML Services stay tuned to every customer instance? We deal with this by providing settings in the request or using tools like LaunchDarkly to provide customer-specific configurations.
ML Services may run ML models directly or invoke other services for model serving, for example, Vertex AI. If the models are running within an ML service, the service will load the trained model from the cloud storage. While we want the same models to be used by all customers, there is a room for serving different versions of the models in the scenario of gradual rollout of new functionalities. This is facilitated by keeping versioned models in the cloud storage.
ML Services also allow us to split traffic between the versions of the code, do canary deployments, or roll back to a previous good version of a service. It is very convenient that we can test Cloud Run services locally because a service is defined by a Dockerfile, which means we can build and run the service on a local machine. Using a Dockerfile allows us not only to install required Python packages, but also to install all additional Linux packages we may need.
We designed ML Services to be accessed with a common URL. To enable this feature, we added an API gateway in front of the ML services. This is required because Cloud Run generates different internal URLs for each service and each version of the service. Without the API management solution, the client applications would have to change the service URL whenever there is an update to the functionality.
API Gateway is a GCP product for managing APIs by providing a low latency, scalable and secure forwarding service. In the API Gateway, we can configure paths to point to an internal URL of an ML service, and this enables us to have the API always point to the latest version of the model. The architecture can be represented using the following diagram:
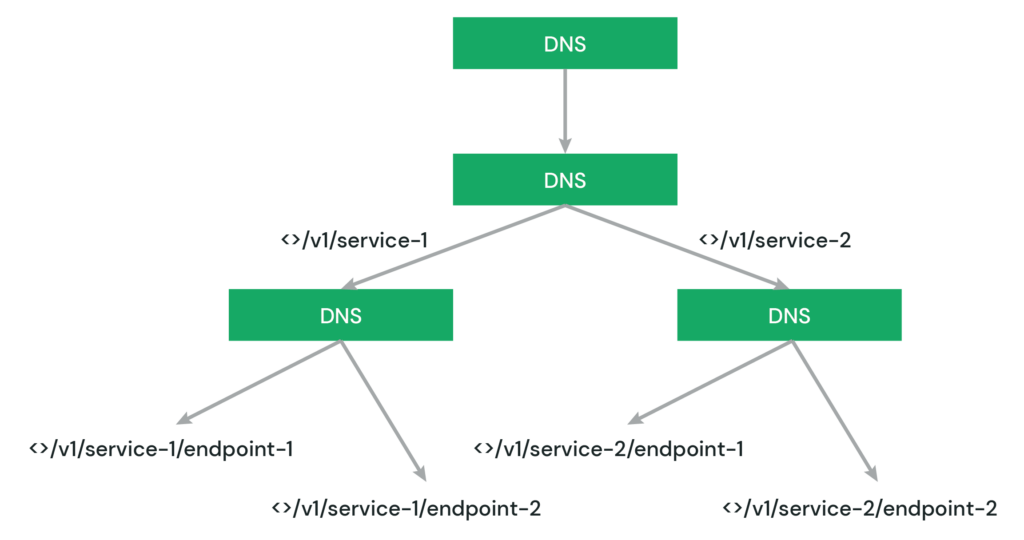
Using API Gateway works as an abstraction layer for many ML services, including multiple versions of the same ML models. A single API gateway also means that we are using only one DNS domain name for all our ML services and API Gateway takes care of routing all requests to their respective ML services based on their path and according to the gateway configuration.
SupportLogic is always striving for efficient engineering processes. One of the principles of efficient ML Ops is Infrastructure as Code. In this case, it means configuring GCP resources, such as Cloud Run and API, and using versioned configuration files and scripts instead of configuring using UI in the GCP console. Both ML Services and API Gateway are configured using YAML files and are deployed using simple commands. This enables us to provision and deploy rapidly all required services in a new environment.
An important part of our deployment automation is using Cloud Build to build docker containers and put them to the Container Registry in GCP. Building containers in the cloud rather than on a developer’s machine enables us to develop software on developer workstation with different processor architectures because container images, built on non-Intel machines, cannot be used for running Cloud Run containers.
Each ML Service has a similar set of files to get it to work:
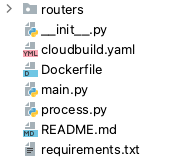
This file is used to install all required Linux and Python packages, copy required files to the container image, set the environment variables, and launch a FastAPI server.
This file manages Python dependencies, both external and internal, including Python packages that were previously copied to the container.
This YAML file contains instructions for building a container image, saving it to GCP Container Registry and deploying it to Cloud Run. Below is a small code snippet from this file to demonstrate the process.
steps:
#Build the container image
- name: 'gcr.io/cloud-builders/docker'
args:
- 'build'
- '--tag=gcr.io/${_PROJECT_ID}/${_IMAGE_NAME}'
- '--file=Dockerfile'
- '.'
# Push the container image to Container Registry
- name: 'gcr.io/cloud-builders/docker'
args: ['push', 'gcr.io/${_PROJECT_ID}/${_IMAGE_NAME}']
#Deploy container image to Cloud Run
- name: 'gcr.io/google.com/cloudsdktool/cloud-sdk'
entrypoint: gcloud
args: ['run', 'deploy', '${_SERVICE_NAME}', '--image', 'gcr.io/${_PROJECT_ID}/${_IMAGE_NAME}', '--region', '${_REGION}']
This file is common for all ML Services and represents an OpenAPI document. Every ML Service has its own internal URL, but the API has a single URL and routes requests to ML services based on the subpaths. A single path element looks like this:
/v1/service-1/endpoint-1:
post:
produces:
- application/json
security:
- api_key: []
x-google-backend:
address: <Internal Service URL>
tags:
- Service 1 tag
summary: Get results from service 1
operationId: ServiceId
responses:
'200':
description: A successful response
"schema": {}
Migrating to the ML Services platform allowed us not only to scale AI in customer service and reduce the load on the back-end application, but also to increase the speed of innovation by taking advantage of faster deployment cycles. Below are the key takeaways we learned during the development of ML Services:
Stay tuned next month for part 3 of our MLaaS journey. To find out more about our approach to machine learning, check out the resources below:
Want the latest B2B Support, AI and ML blogs delivered straight to your inbox?


